
Week4. 데이터를 저장하는 방법
수집한 데이터를 원하는 파일 형식(엑셀, csv)으로 저장하는 법을 알아볼 것
1. 파이썬으로 파일 만들기
파일 만들기 기본
파이썬 파일 변수 이해하기
출력문을 통해 파이참 검은 화면에 출력한 데이터는 일회성이다. 따라서 값을 저장하고 다시 사용하기 위해서는 파일로 변환해야 한다.
f = open('text.txt', 'w')
f.close()이를 실행시키면 text.txt라는 파일이 생겼음을 볼 수 있다.
이때 주의할 것
파일변수.close()를 꼭 해줄 것.
그냥 open함수를 쓰면 close함수도 동시에 써주도록 해라.
열린 파일을 닫지 않으면 컴퓨터의 어딘가에 파일이 열린 상태로 유지된다.
open이라는 함수는 앞에 나오는 파일 이름 text.txt를 w(write)형식으로 열어달라는 의미이다. 따라서 이 소스코드가 위치한 폴더에 text.txt가 만들어진 것을 확인할 수 있다.
파일변수 f는 open함수를 통해 열 수 있다.
파일변수 = open(파일이름, '오픈형식')
파일 오픈 형식
- w : (write 모드) 새로 파일을 쓸 때 사용
- r : (read 모드) 파일로부터 데이터를 읽고 싶을 때 사용
- a : (append 모드) 파일에 데이터를 추가로 쓰고 싶을 때 사용
# f에 파일을 저장
f = open('text.txt', 'w')
# f에 파일을 쓰기
f.write('Hello world!')
f.write('Good bye!')
f.close()
이때, pycharm에서 해당 파일을 우클릭한 후
reveal in finder를 클릭하면 해당 파일이 저장되어있는 폴더가 열린다.
2. 데이터 csv파일로 저장하기
파이썬으로 csv파일 쓰기
csv : comma separated value
콤마로 구분되는 값들의 모음
값들의 열구분(가로 데이터 구분)은 콤마,
값들의 행구분(세로 데이터 구분)은 엔터\n

f = open("hitsong.csv", "w")
capital_letter = ['A', 'B', 'C', 'D', 'E']
small_letter = ['a', 'b', 'c', 'd', 'e']
for i in range(len(capital_letter)):
f.write(capital_letter[i]+','+small_letter[i]+'\n')
f.close()이때 csv파일을 오픈할때 엑셀에서 한글이 깨지는 경우가 발생할 수 있다.
그럴때에는 open함수에 encoding옵션을 추가해주자.f = open("hitsong.csv", "w", encoding = "UTF-8")
데이터 수집결과 csv로 저장하기
csv저장방식을 week3에서 만든 데이터 수집에 적용해보자.
네이버 tv의 1,2,3순위에 대한 데이터 정보를 크롤링한 것을 csv로 저장해보자.
import requests
from bs4 import BeautifulSoup
# csv형식으로 저장하기
f = open("navertv.csv", "w")
# 수집한 데이터가 어떤 데이터인 header를 넣어주는 것이 중요하다.
f.write("제목, 채널명, 재생수, 좋아요\n")
raw = requests.get("https://tv.naver.com/r/")
html = BeautifulSoup(raw.text, 'html.parser')
container = html.select("div.inner")
for cont in container:
title = cont.select_one("dt.title").text.strip()
chn = cont.select_one("dd.chn").text.strip()
hit = cont.select_one("span.hit").text.strip()
like = cont.select_one("span.like").text.strip()
f.write(title+","+chn+","+hit+","+like+"\n")
# 위에서 open함수를 썼을때 필수적으로 써주다시피 해주자.
f.close()
그런데......결과는....

원하는 결과가 나오지 않았다. 이는 의도치 않은 콤마,가 수집한 데이터 안에 있었기 때문이다. 따라서 csv가 이 콤마를 텍스트 안의 콤마인지, 열을 나누기 위해 사용한 콤마인지 구분할 수 없기 때문.
그러니 replace()함수를 사용하여 이 콤마를 삭제해주자.
f = open("navertv.csv", "w")
# 수집한 데이터가 어떤 데이터인 header를 넣어주는 것이 중요하다.
f.write("제목, 채널명, 재생수, 좋아요\n")
raw = requests.get("https://tv.naver.com/r/")
html = BeautifulSoup(raw.text, 'html.parser')
container = html.select("div.inner")
for cont in container:
title = cont.select_one("dt.title").text.strip().replace(",", "")
chn = cont.select_one("dd.chn").text.strip().replace(",", "")
hit = cont.select_one("span.hit").text.strip().replace(",", "")
like = cont.select_one("span.like").text.strip().replace(",", "")
f.write(title+","+chn+","+hit+","+like+"\n")
f.close()

이때, 우리가 재생수나 좋아요수를 구하고서 평균값을 알고싶을 수 있다. 그러기 위해서 재생수와 좋아요라는 텍스트를 없애보자.
import requests
from bs4 import BeautifulSoup
# csv형식으로 저장하기
f = open("navertv.csv", "w")
# 수집한 데이터가 어떤 데이터인 header를 넣어주는 것이 중요하다.
f.write("제목, 채널명, 재생수, 좋아요\n")
raw = requests.get("https://tv.naver.com/r/")
html = BeautifulSoup(raw.text, 'html.parser')
container = html.select("div.inner")
for cont in container:
title = cont.select_one("dt.title").text.strip().replace(",", "")
chn = cont.select_one("dd.chn").text.strip().replace(",", "")
hit = cont.select_one("span.hit").text.strip().replace(",", "").replace("재생 수", "")
like = cont.select_one("span.like").text.strip().replace(",", "").replace("좋아요 수", "")
f.write(title+","+chn+","+hit+","+like+"\n")
f.close()
3. 데이터 엑셀파일로 저장하기
파이썬으로 엑셀파일 쓰기(openPyXL)
openPyXL이라는 오픈소스패키지를 사용하여 엑셀형식으로 데이터를 저장해보자. 이러한 openPyXL은 엑셀2010의 xlsx/xlsm/xltx/xltm파일을 읽고 쓸 수 있는 파이썬 오픈소스 라이브러리이다. 파일의 저장뿐 아니라 엑셀 프로그램을 켜서 할 수 있는 모든 일을 할 수 있다.
실습을 하기에 앞서 파이참 터미널에서pip3 install openpyxl
를 실행하여 openpyxl을 설치해주자.
# openpyxl 연습하기
import openpyxl
# wb는 workbook의 약자
wb = openpyxl.Workbook() # 새로운 workbook..즉 엑셀 파일을 만들어달라는 것
wb.save("text.xlsx")
# 실행하고 나면 text.xlsx 파일이 생겼음을 볼 수 있다.openPyXL 패키지의 좋은 점은 우리가 엑셀에서 하는 행동을 1대1로 바꿔준다는 것이다.
실제로 엑셀에서 파일을 만들면 저장되지 않은 빈 파일이 wb에 저장된다 생각하면 되고, wb.save('특정파일이름')으로 파일을 만들었을때... 엑셀파일이 만들어지게 된다.
그럼 가장 간단한 파일 입력법에 대해 알아보자.
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active # 현재 활성화 되어있는 엑셀 파일의 시트를 의미한다.
sheet['A1'] = "Hello World"
wb.save("text.xlsx")파일의 A1 자리에 Hello World가 들어간 것을 확인할 수 있다.

가장 기본적인 데이터 저장방법은
- 파일변수 wb를 만들어 현재 활성화된 시트에
- A1에 해당하는 셀번호에 원하는 데이터를 넣을 수 있다.
마찬가지로 엑셀 프로그램에서 - 시트를 선택하고
- 특정 셀을 선택하여 거기에 데이터를 넣는 것과 같은 방식이다.
하지만 이 방식은 내가 셀 번호를 정확히 알아야 하기 때문에 데이터를 여러개 넣어야 할때 불편할 수 있다. 따라서 다음과 같은 방법을 사용해보자.
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet['A1'] = "Hello World"
# 3행 3열의 데이터에 Good Bye를 넣어주겠다는 것.
sheet.cell(row = 3, column = 3).value = "Good Bye"
wb.save("text.xlsx")이러한sheet.cell(row = 3, column = 3).value = "Good Bye"
로 입력하는 방식은 반복문을 통해서 지속적으로 특정 셀에 데이터를 입력하는 것도 용이하다.

앞으로 가장 많이 사용할 방법은 다음과 같다.
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet['A1'] = "Hello World"
sheet.cell(row = 3, column = 3).value = "Good Bye"
sheet.append(["Python", "Java", "HTML", "Javascript"])
# append의 경우 데이터의 위치와 상관없이 지금 내가 연 엑셀파일의 가장 아래에 데이터들을 저장해줌.
# 행별로 데이터를 추가한다
sheet.append(["Coala", "Study", "Crawling"])
wb.save("text.xlsx")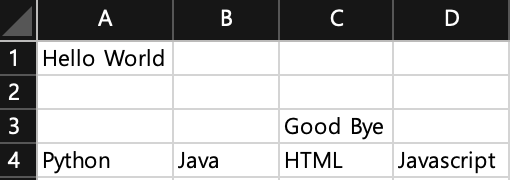
데이터 수집을 할때에는 행별로 데이터를 추가하는 경우가 많기에 이러한 sheet.append로 데이터를 추가하는 일이 많을 것이다.
데이터 수집결과 엑셀로 저장하기
저번에 한 네이버 tv 데이터 수집결과를 엑셀로 저장해보자.
import requests
from bs4 import BeautifulSoup
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["제목", "채널명", "재생수", "좋아요수"])
# \n을 넣어주지 않아도 됨.
# 어차피 append는 그 다음줄인 새줄에서 데이터를 추가하기 때문.
raw = requests.get("https://tv.naver.com/r/")
html = BeautifulSoup(raw.text, 'html.parser')
container = html.select("div.inner")
for cont in container:
title = cont.select_one("dt.title").text.strip().replace(",", "")
chn = cont.select_one("dd.chn").text.strip().replace(",", "")
hit = cont.select_one("span.hit").text.strip().replace(",", "").replace("재생 수", "")
like = cont.select_one("span.like").text.strip().replace(",", "").replace("좋아요 수", "")
sheet.append([title, chn, hit, like ])
# 여기서의 콤마 , 는 리스트 안에서의 데이터를 구분해주는 콤마이다.
wb.save("navertv.xlsx")
# 이번엔 navertv.xlsx파일이 저장되었음을 확인할 수 있다.
이러한 openPyXL을 사용하면 콤마,나 csv가 가지는 약점이 극복되기에 이러한 openPyXL을 사용하는 것이 조금더 권장된다.
기본적으로 데이터를 csv로 저장하든, 엑셀형식으로 저장하든 본인이 필요한 양식에 맞게 저장하면 된다.
맨 첫번째 줄 header엔 데이터의 구분값이 나오고 두번째줄부터 헤더에 해당하는 데이터가 오는 것이 데이터 분석이나 수집에서 기본적으로 사용하는 양식이다.
따라서 수집한 데이터를 저장할땐 첫번째줄에 header를 꼭 넣어주도록 하자.
4. 엑셀파일 저장하기/심화
엑셀 심화 : 엑셀 파일 불러오기
다양한 방법으로 데이터를 예쁘게 저장할 수 있는 법에 대해 알아보자.
네이버 뉴스 검새결과에 대한 데이터 수집을 하였는데..
이번엔 검색어도 프로그램 안에서 입력할 수 있도록 만들어보자.
import requests
from bs4 import BeautifulSoup
keyword = input("어떤 검색어에 대해서 알고싶니? : ")
print("*"*80)
for page in range(1, 100, 10):
raw = requests.get("https://search.naver.com/search.naver?where=news&query="+keyword+"&start="+str(page),
headers={"User-Agent": "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select("ul.type01 > li")
for ar in articles:
title = ar.select_one("ul.type01 > li a._sp_each_title").text.replace(",","")
source = ar.select_one("ul.type01 > li span._sp_each_source").text
print(title, source, sep = " - ")
print("="*60)
이제 이러한 결과를 엑셀에다가 저장해보자.
import requests
from bs4 import BeautifulSoup
import openpyxl
keyword = input("어떤 검색어에 대해서 알고싶니? : ")
print("*"*80)
wb = openpyxl.Workbook()
sheet = wb.active
# header추가
sheet.append(["제목", "언론사"])
for page in range(1, 100, 10):
raw = requests.get("https://search.naver.com/search.naver?where=news&query="+keyword+"&start="+str(page),
headers={"User-Agent": "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select("ul.type01 > li")
for ar in articles:
title = ar.select_one("ul.type01 > li a._sp_each_title").text.replace(",","")
source = ar.select_one("ul.type01 > li span._sp_each_source").text
print(title, source, sep = " - ")
sheet.append([title, source])
print("="*60)
wb.save("navernews.xlsx")
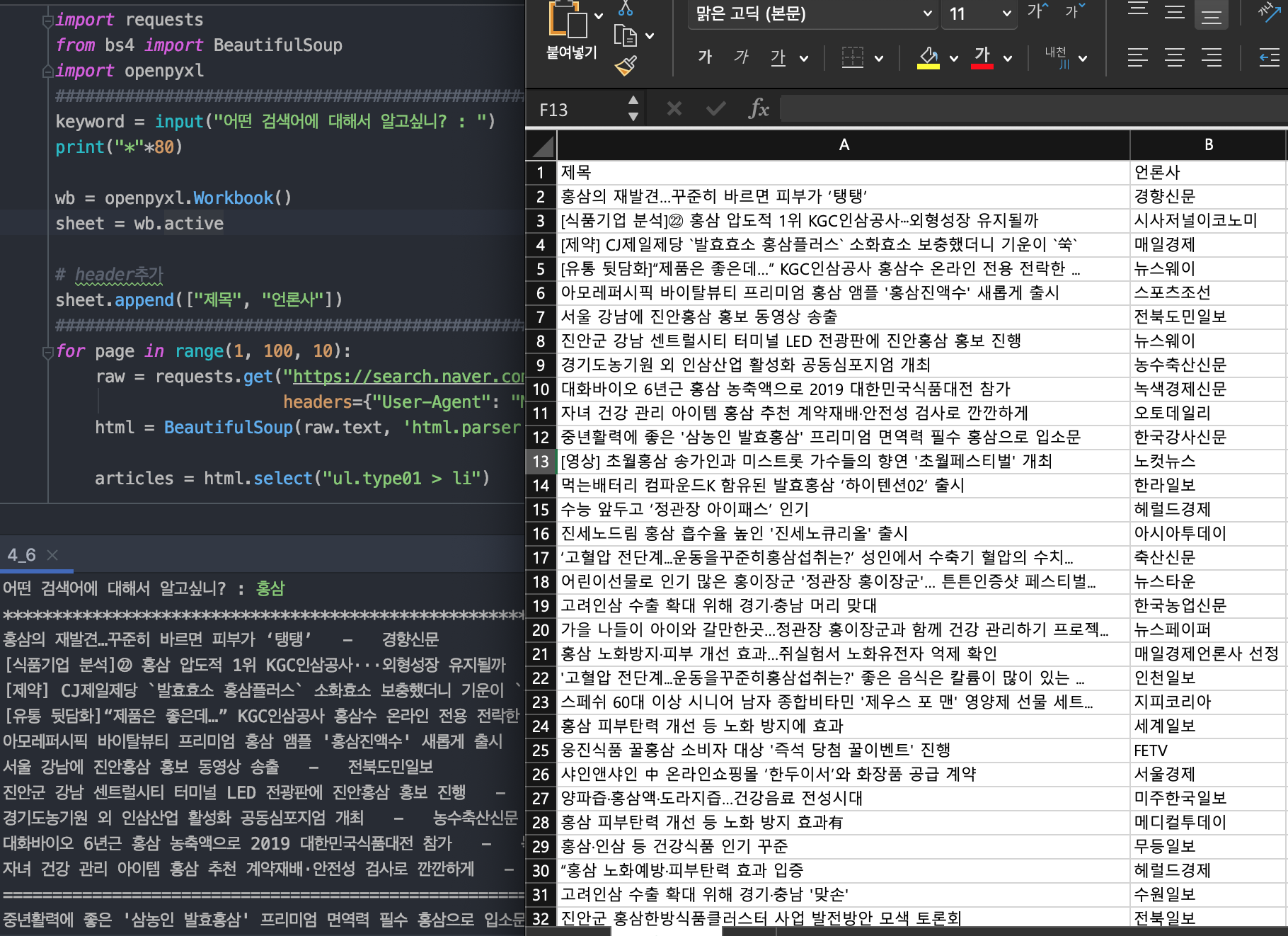
엑셀 심화 : 상황에 따라 다르게 쓰기
위에서 만든 데이터 수집기에는 치명적인 약점이 존재한다.
가령 keyword1을 검색해서 생긴 file.xlsx가 있을때, 다시 keyword2를 검색하면 기존에 있던 file.xlsx 파일에 덮여서 저장된다.
그래서 이번엔 새로운 키워드를 검색할때마다 기존의 데이터 밑에 새로운 키워드를 검색해서 얻어낸 데이터를 추가해보고싶다면?
openPyXL의 load_workbook을 활용해보자.
import requests
from bs4 import BeautifulSoup
import openpyxl
keyword = input("어떤 검색어에 대해서 알고싶니? : ")
print("*"*80)
# 새로운 키워드를 검색할때마다 기존의 파일인 navernews.xlsx 밑에 이어서 데이터가 저장되도록 해보자.
wb = openpyxl.load_workbook("navernews.xlsx")
# wb = openpyxl.Workbook()
sheet = wb.active
# header추가
sheet.append(["제목", "언론사"])
for page in range(1, 100, 10):
raw = requests.get("https://search.naver.com/search.naver?where=news&query="+keyword+"&start="+str(page),
headers={"User-Agent": "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select("ul.type01 > li")
for ar in articles:
title = ar.select_one("ul.type01 > li a._sp_each_title").text.replace(",","")
source = ar.select_one("ul.type01 > li span._sp_each_source").text
print(title, source, sep = " - ")
sheet.append([title, source])
print("="*60)
wb.save("navernews.xlsx")처음 검색한 키워드로부터 얻어낸 기존의 파일 밑에 새로운 키워드를 검색해서 얻어낸 새로운 데이터가 누적돼서 저장되었음을 확인할 수 있다.
그런데... 여전히 약점은 존재한다.
우리가 불러오려는 파일이 있을때는 데이터를 잘 불러와서 새로 수집한 데이터를 잘 누적할 수 있지만...
이 코드를 처음 실행했을 때 기존의 파일이 없는 경우 오류가 발생한다.wb = openpyxl.load_workbook("navernews.xlsx")
여기서 불러오는 함수 자체는 기존의 파일인 navernews.xlsx가 존재해야만 불러올 수 있기 때문이다.
그래서 두가지 상황에서 서로 다르게 작성하는 코드를 만들고싶다.
기존의 파일이 없으면 새로 만들어서 데이터를 저장하고, 기존의 파일이 있다면 그 파일을 불러와서 수집한 데이터를 누적해서 저장하려는 프로그램을 만들어보자.
try, except문을 활용해보자
import requests
from bs4 import BeautifulSoup
import openpyxl
keyword = input("어떤 검색어에 대해서 알고싶니? : ")
print("*"*80)
try:
wb = openpyxl.load_workbook("navernews.xlsx")
sheet = wb.active # try에도 시트를 지정해주는 부분이 필요하므로 추가해준다.
# try밑에 부분을 시도해봤는데 이러가 발생할 경우
# except 밑이 코드가 실행이 된다.
# try를 썼는지 구분해주기 위해 한번 출력문을 써보자.
print("기존의 파일 불러오기 완료")
except :
wb = openpyxl.Workbook()
sheet = wb.active
# header추가
sheet.append(["제목", "언론사"])
# except를 썼는지 구분해주기 위해 출력문 작성
print("새로운 파일 생성 완료")
for page in range(1, 100, 10):
raw = requests.get("https://search.naver.com/search.naver?where=news&query="+keyword+"&start="+str(page),
headers={"User-Agent": "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select("ul.type01 > li")
for ar in articles:
title = ar.select_one("ul.type01 > li a._sp_each_title").text.replace(",","")
source = ar.select_one("ul.type01 > li span._sp_each_source").text
print(title, source, sep = " - ")
sheet.append([title, source])
print("="*60)
wb.save("navernews.xlsx")
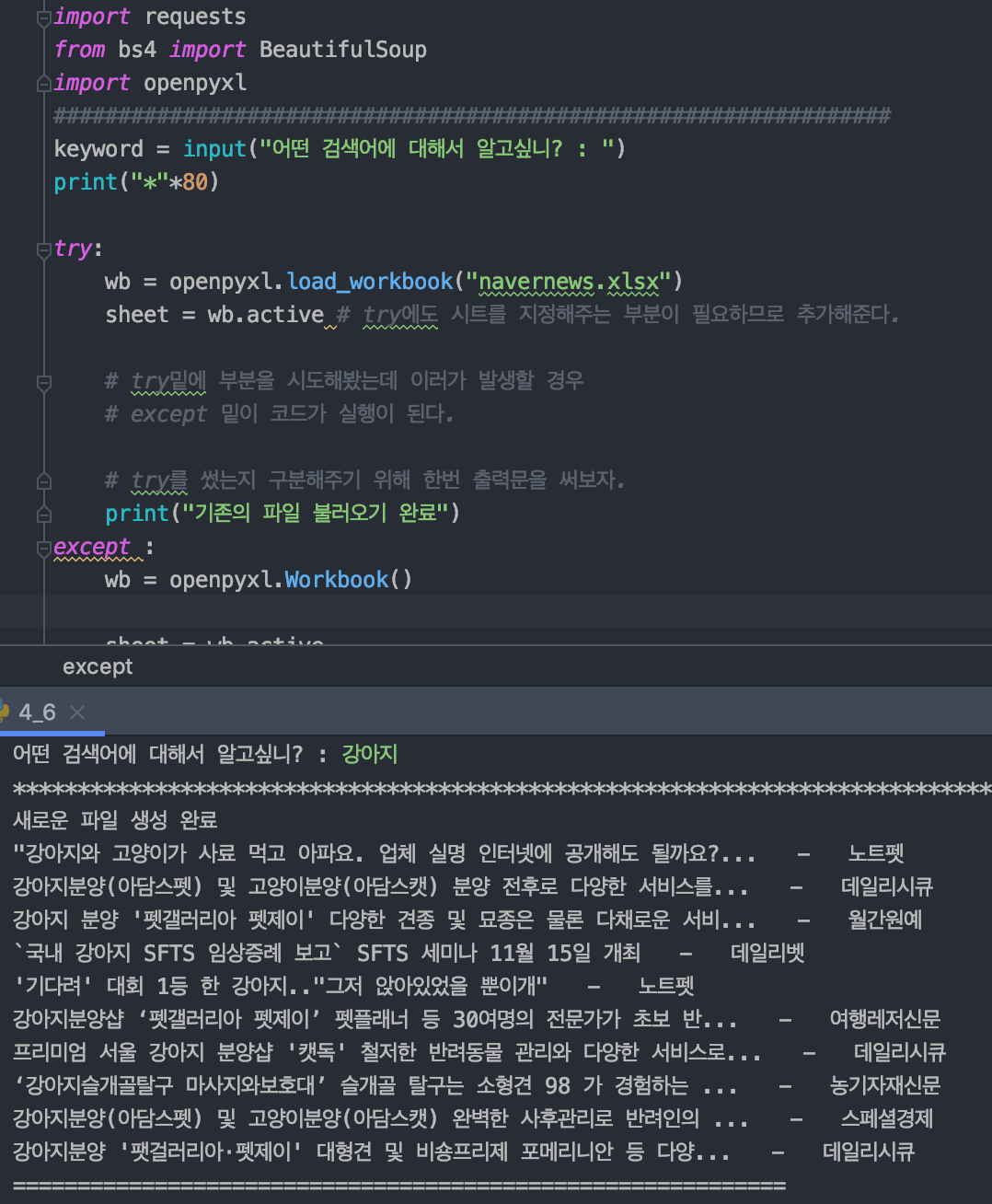

새로운 파일 작성했을때 화면과 불러오기 완료됐을때의 화면 넣기
이렇게 데이터를 누적해서 계속 수행할 수도 있고, try문을 이용하여 상황에 따라 다른 방법으로 코드를 실행시킬 수 있는 방법에 대하여 공부해보았다.
'Data_Analysis' 카테고리의 다른 글
| [코알라univ] 5_2. 똑똑하게 데이터 수집하기 (0) | 2019.11.08 |
|---|---|
| [코알라univ] 5_1. 똑똑하게 데이터 수집하기 (0) | 2019.11.08 |
| [코알라univ]3_3. 파이썬으로 데이터 수집하기 (0) | 2019.10.29 |
| [코알라univ]3_2. 파이썬으로 데이터 수집하기 (0) | 2019.10.28 |
| [코알라univ]3_1. 파이썬으로 데이터 수집하기 (0) | 2019.10.14 |