
challenge 1. IMDb에서 영화 정보 수집하기
IMDb페이지에서 현재 상영 중인 영화의 1. 제목 / 감독 / 배우 찾기
그러고서 2. Action장르의 영화만 출력하기
1. 제목 / 감독 / 배우 찾기
import requests
from bs4 import BeautifulSoup
raw = requests.get("https://www.imdb.com/movies-in-theaters/?ref_=nv_mv_inth",
headers = {"User-Agent" : "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
movies = html.select("td.overview-top")
# 컨테이너 : td.overview-top
# 제목 : td.overview-top h4 a
# 감독 : td.overview-top> div:nth-of-type(3) a
# 배우 : td.overview-top> div:nth-of-type(4) a
for movie in movies:
title = movie.select_one("td.overview-top h4 a").text
# 감독, 배우는 2명 이상인 경우가 있으므로 select를 활용하여 리스트로 저장한다.
directors = movie.select("td.overview-top> div:nth-of-type(3) a")
actors = movie.select("td.overview-top> div:nth-of-type(4) a")
print("영화 제목 : ",title)
print("감독 :", end=" ")
for director in directors:
print(director.text, end =" ")
print() # 줄바꿈 해주기 위함
print("배우 :", end=" ")
for actor in actors :
print(actor.text, end = " ")
print() # 줄바꿈 해주기 위함
print("="*50)
위에서 얻은 데이터를 엑셀 파일로 저장해보자.
import requests
from bs4 import BeautifulSoup
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["영화제목", "감독", "배우"])
raw = requests.get("https://www.imdb.com/movies-in-theaters/?ref_=nv_mv_inth",
headers = {"User-Agent" : "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
movies = html.select("td.overview-top")
# 컨테이너 : td.overview-top
# 제목 : td.overview-top h4 a
# 감독 : td.overview-top> div:nth-of-type(3) a
# 배우 : td.overview-top> div:nth-of-type(4) a
for movie in movies:
title = movie.select_one("td.overview-top h4 a").text
# 감독, 배우는 2명 이상인 경우가 있으므로 select를 활용하여 리스트로 저장한다.
directors = movie.select("td.overview-top> div:nth-of-type(3) a")
actors = movie.select("td.overview-top> div:nth-of-type(4) a")
print("영화 제목 : ",title)
director_list = []
actor_list = []
print("감독 :", end=" ")
for director in directors:
print(director.text, end =" ")
director_list.append(director.text)
Directors = ", ".join(director_list)
print()
print("배우 :", end=" ")
for actor in actors :
print(actor.text, end = " ")
actor_list.append(actor.text)
Actors = ", ".join(actor_list)
print()
print("="*50)
sheet.append([title, Directors, Actors])
wb.save("imdbin_info.xlsx")
이제 액션 장르만 추려보자.
import requests
from bs4 import BeautifulSoup
raw = requests.get("https://www.imdb.com/movies-in-theaters/?ref_=nv_mv_inth",
headers = {"User-Agent" : "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
movies = html.select("td.overview-top")
# 컨테이너 : td.overview-top
# 제목 : td.overview-top h4 a
# 감독 : td.overview-top> div:nth-of-type(3) a
# 배우 : td.overview-top> div:nth-of-type(4) a
for movie in movies:
title = movie.select_one("td.overview-top h4 a").text
directors = movie.select("td.overview-top> div:nth-of-type(3) a")
actors = movie.select("td.overview-top> div:nth-of-type(4) a")
# 액션 장르가 아닌 경우에 continue문을 통해 아래 문장들은 실행하지 않고 다시 위로 올라간다.
genre = movie.select_one("p.cert-runtime-genre").text
if "Action" not in genre:
continue
########################################
print("영화 제목 : ",title)
print("감독 :", end=" ")
for director in directors:
print(director.text, end =" ")
print() # 줄바꿈 해주기 위함
print("배우 :", end=" ")
for actor in actors :
print(actor.text, end = " ")
print() # 줄바꿈 해주기 위함
print("="*50)
challenge 2. IMDb에서 영화 포스터 저장하기
challenge 1의 코드를 활용하여 각 영화 상세 페이지에 접속하여 포스터를 저장한다.
import requests
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
raw = requests.get("https://www.imdb.com/movies-in-theaters/?ref_=nv_mv_inth",
headers = {"User-Agent" : "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
movies = html.select("td.overview-top")
# 컨테이너 : td.overview-top
# 제목 : td.overview-top h4 a
# 감독 : td.overview-top> div:nth-of-type(3) a
# 배우 : td.overview-top> div:nth-of-type(4) a
for movie in movies:
title = movie.select_one("td.overview-top h4 a")
url = title.attrs["href"]
# 감독, 배우는 2명 이상인 경우가 있으므로 select를 활용하여 리스트로 저장한다.
directors = movie.select("td.overview-top> div:nth-of-type(3) a")
actors = movie.select("td.overview-top> div:nth-of-type(4) a")
print("영화 제목 : ",title.text)
print("감독 :", end=" ")
for director in directors:
print(director.text, end =" ")
print() # 줄바꿈 해주기 위함
print("배우 :", end=" ")
for actor in actors :
print(actor.text, end = " ")
print() # 줄바꿈 해주기 위함
print("="*50)
each_raw = requests.get("https://www.imdb.com"+url,
headers = {"User-Agent" : "Mozilla/5.0"})
each_html = BeautifulSoup(each_raw.text, 'html.parser')
# poster 선택자 : div.mv_info_area div.poster img
poster = each_html.select_one("div.poster img")
poster_src = poster.attrs["src"]
urlretrieve(poster_src, "poster2/"+title.text.strip().replace(":","")+".png")
homework. 다음 영화 데이터 수집하기
다음 영화의 예매순위 페이지에서 영화의 제목, 평점, 장르, 감독, 배우 데이터 수집하기.
-
hint) 다음영화 예매페이지의 경우, a태그에 저장되있는 링크는 완벽한 URL의 형태를 띄고 있습니다. 굳이 기존페이지의 주소를 붙여주지 않아도 상관없음
-
hint) 영화의 상세페이지가 없는 경우에 에러가 발생할 수 있으니 확인하시고 코드를 완성하자
# 컨테이너 : ul.list_boxthumb li
# 제목 : ul.list_boxthumb li strong a
# 평점 : ul.list_boxthumb li em.emph_grade
# 장르 : dl.list_main dd:nth-of-type(1)
# 감독 : dl.list_main dd:nth-of-type(5)
# 배우 : dl.list_main dd:nth-of-type(6)
import requests
from bs4 import BeautifulSoup
raw = requests.get("http://ticket2.movie.daum.net/Movie/MovieRankList.aspx",
headers = {"User-Agent" : "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
movies = html.select("ul.list_boxthumb li")
for movie in movies :
title = movie.select_one("ul.list_boxthumb li strong a")
url = title.attrs["href"]
each_raw = requests.get(url,
headers = {"User-Agent" : "Mozilla/5.0"})
each_html = BeautifulSoup(each_raw.text, 'html.parser')
genre = each_html.select_one("dl.list_main dd:nth-of-type(1)")
directors = each_html.select("dl.list_main dd:nth-of-type(5) a")
actors = each_html.select("dl.list_main dd:nth-of-type(6) a")
print("영화 제목 : ",title.text.strip())
print("영화 장르 : ", genre.text)
print("감독 : ", end="")
for director in directors:
print(director.text.strip(), end = " ")
print()
print("배우 : ", end="")
for actor in actors :
print(actor.text.strip(), end = " ")
print()
print("="*50)
이제 이렇게 수집한 데이터를 엑셀로 저장해보자.
# 컨테이너 : ul.list_boxthumb li
# 제목 : ul.list_boxthumb li strong a
# 평점 : ul.list_boxthumb li em.emph_grade
# 장르 : dl.list_main dd:nth-of-type(1)
# 감독 : dl.list_main dd:nth-of-type(5)
# 배우 : dl.list_main dd:nth-of-type(6)
import requests
from bs4 import BeautifulSoup
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["제목", "장르", "감독", "배우"])
raw = requests.get("http://ticket2.movie.daum.net/Movie/MovieRankList.aspx",
headers = {"User-Agent" : "Mozilla/5.0"})
html = BeautifulSoup(raw.text, 'html.parser')
movies = html.select("ul.list_boxthumb li")
for movie in movies :
title = movie.select_one("ul.list_boxthumb li strong a")
url = title.attrs["href"]
each_raw = requests.get(url,
headers = {"User-Agent" : "Mozilla/5.0"})
each_html = BeautifulSoup(each_raw.text, 'html.parser')
genre = each_html.select_one("dl.list_main dd:nth-of-type(1)")
directors = each_html.select("dl.list_main dd:nth-of-type(5) a")
actors = each_html.select("dl.list_main dd:nth-of-type(6) a")
directors_list = []
actors_list = []
print("영화 제목 : ",title.text.strip())
print("영화 장르 : ", genre.text)
print("감독 : ", end="")
for director in directors:
print(director.text.strip(), end = " ")
directors_list.append(director.text)
Directors = ",".join(directors_list)
print()
print("배우 : ", end="")
for actor in actors :
print(actor.text.strip(), end = " ")
actors_list.append(actor.text)
Actors = ",".join(actors_list)
print()
print("="*50)
sheet.append([title.text.strip(), genre.text, Directors, Actors])
wb.save("daum_moive_info.xlsx")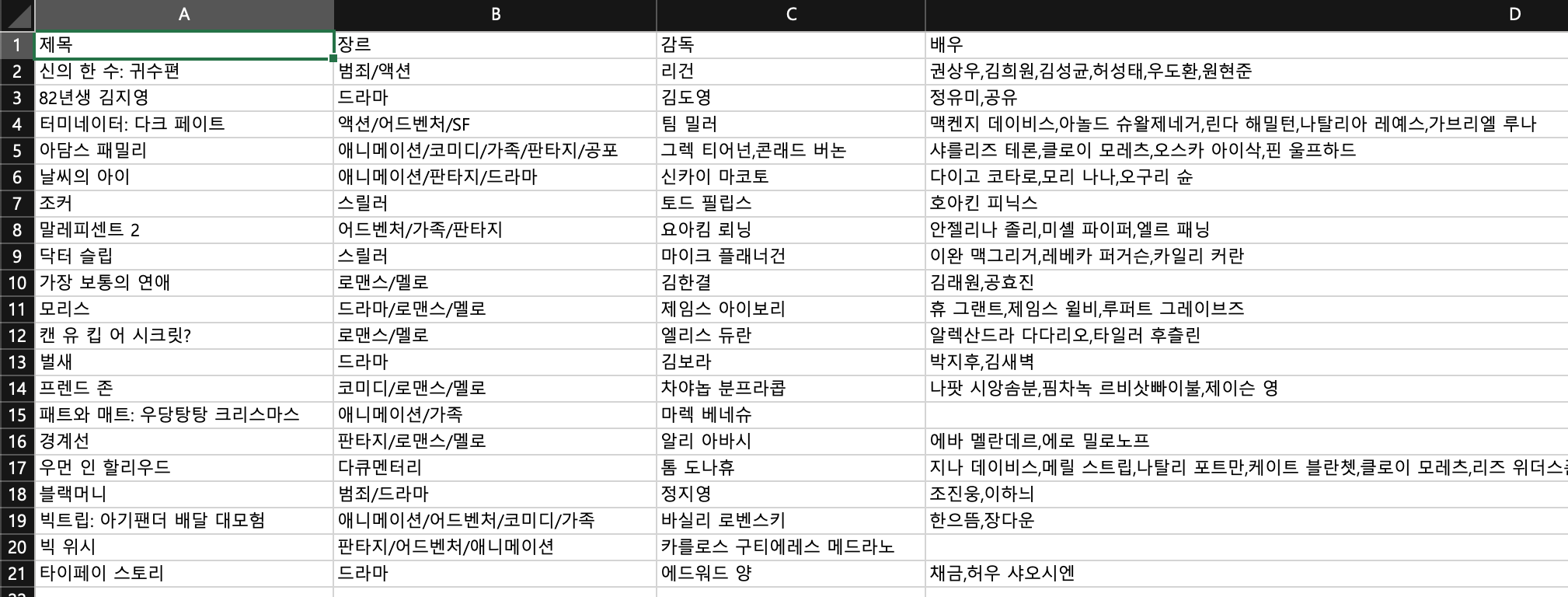
짜잔! 열심히 컴퓨터에게 명령해서 수집한 결과를 엑셀로 저장하기까지 배웠다.
week5는 헷갈리는 부분이 많으니 복습을 꼭 많이 해주자...^-^
반응형
'Data_Analysis' 카테고리의 다른 글
| [코알라univ] 5_1. 똑똑하게 데이터 수집하기 (0) | 2019.11.08 |
|---|---|
| [코알라univ]4. 데이터를 저장하는 방법 (0) | 2019.10.30 |
| [코알라univ]3_3. 파이썬으로 데이터 수집하기 (0) | 2019.10.29 |
| [코알라univ]3_2. 파이썬으로 데이터 수집하기 (0) | 2019.10.28 |
| [코알라univ]3_1. 파이썬으로 데이터 수집하기 (0) | 2019.10.14 |